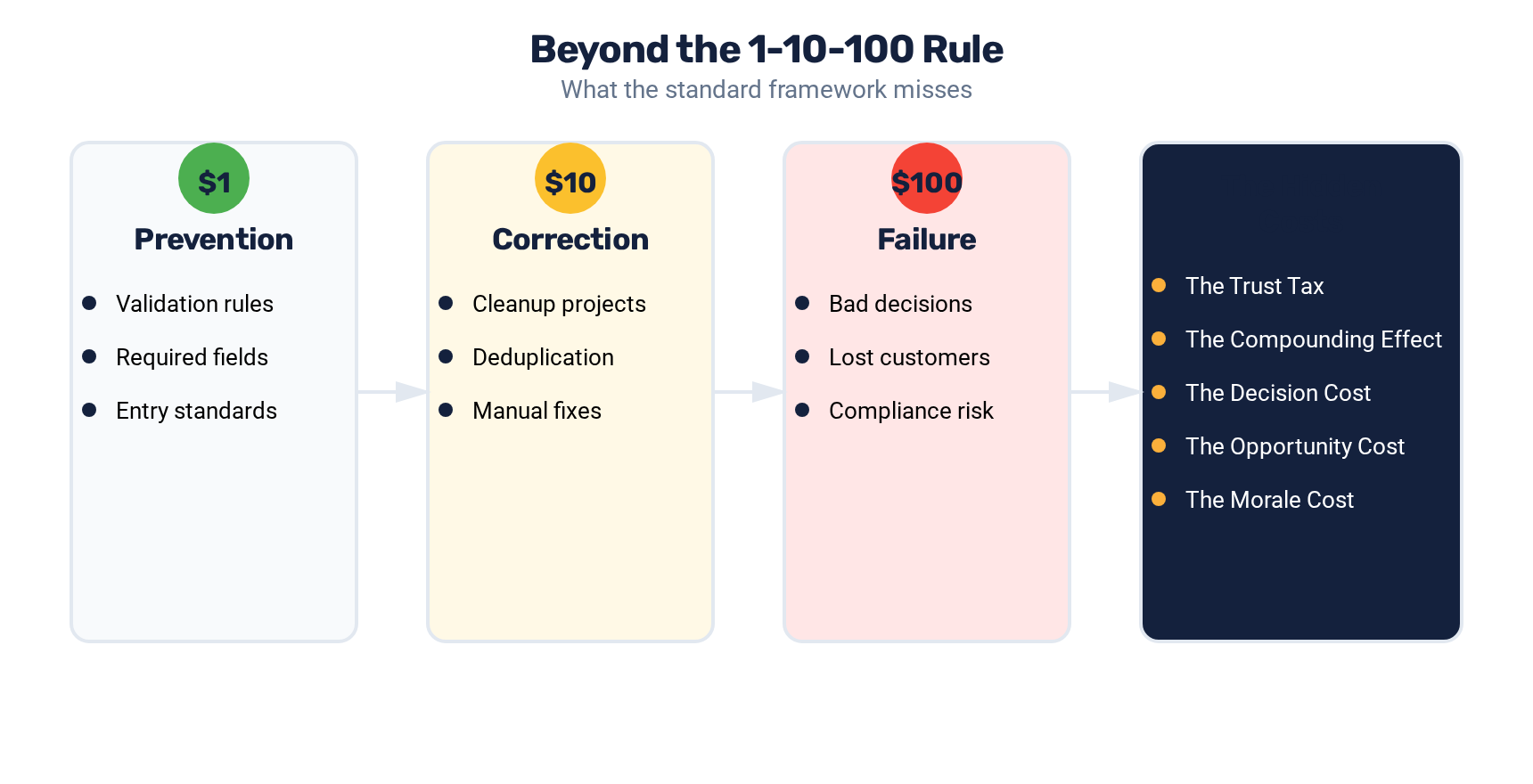
The 1-10-100 rule is the most commonly cited framework in data quality discussions: it costs $1 to verify a record at the point of entry, $10 to clean it after it enters your system, and $100 to address the consequences of leaving it dirty. It is a useful framework for illustrating the cost escalation of deferred data maintenance.
It is also a massive undercount.
The 1-10-100 rule only captures the direct, operational costs of bad data. It misses the strategic, organizational, and compound costs that make bad data one of the most expensive problems in modern business.
The Costs the 1-10-100 Rule Misses
The Trust Tax
When teams do not trust the data in the CRM, they build workarounds. Sales reps maintain their own spreadsheets. Marketing managers export data and manipulate it in Excel before presenting it. Finance creates parallel tracking systems.
Every workaround is a tax on productivity. Instead of one system of record that everyone trusts, you have five shadow systems that nobody maintains consistently. The labor hours spent on these workarounds — building, updating, reconciling, and defending them — are invisible on any budget line but enormous in aggregate.
We have seen organizations where senior leaders spend 15-20% of their time reconciling conflicting data from different sources before they can make a single decision. For a leadership team with a combined compensation of $2M, that is $300,000-$400,000 annually in data reconciliation alone.
The Compounding Effect
Bad data does not stay bad in isolation. It propagates through every system it touches. A wrong industry classification on a contact record flows into lead scoring (wrong score), segmentation (wrong segment), reporting (wrong metrics), territory assignment (wrong rep), and forecasting (wrong prediction).
Each downstream system that consumes the bad data makes its own decisions based on flawed input. Those decisions create new data points that are also flawed. Over time, the error compounds until the gap between what your data says and what reality looks like becomes unbridgeable without a complete reset.
The Decision Cost
Every strategic decision based on bad data carries risk. If your customer segmentation data is wrong, you target the wrong market. If your attribution data is wrong, you invest in the wrong channels. If your churn data is wrong, you misallocate retention resources.
These are not theoretical risks. We have worked with companies that discovered they had been targeting the wrong ICP for years because their CRM data misrepresented who their best customers actually were. The revenue impact of years of misdirected go-to-market investment is incalculable.
The Opportunity Cost
Bad data does not just lead to wrong decisions — it prevents good ones. When you cannot trust your data, you cannot identify opportunities that the data would reveal if it were accurate.
Which accounts are showing buying signals? You do not know because the activity data is incomplete. Which segments have the highest lifetime value? You cannot tell because the revenue data is not properly attributed. Which marketing channels drive the most efficient pipeline? The attribution data is too messy to answer the question.
Every insight you cannot extract because the data is unreliable is an opportunity you cannot act on.
The Morale Cost
Data quality has a real impact on employee experience, particularly for revenue teams that interact with the CRM daily. Reps who encounter duplicate records, missing information, and conflicting data points throughout their day experience friction that slows them down and frustrates them.
Over time, this friction drives a vicious cycle: bad data reduces CRM usage, which reduces data input, which makes the data worse, which further reduces usage. The end state is a CRM that nobody trusts, nobody uses, and nobody maintains — but that the company is still paying for.
Calculating Your Organization's True Data Cost
To get a realistic picture of what bad data costs your organization, add up these categories:
Direct labor costs. Estimate the hours your team spends on data-related workarounds — manual list cleaning, report reconciliation, duplicate management, re-entering information. Multiply by fully loaded labor costs.
Tool waste. Identify tools and features you pay for but cannot use effectively because the data is not clean enough. A marketing automation platform is only as good as the data it operates on. If 30% of your contact data is unreliable, you are getting 30% less value from your automation investment.
Revenue impact. Calculate the revenue implications of forecasting inaccuracy, misrouted leads, broken automations, and misdirected marketing spend. Even conservative estimates of 5-10% revenue impact translate to significant dollars for most organizations.
Opportunity cost. Estimate the value of strategic decisions you cannot make or insights you cannot extract because the data is unreliable. This is harder to quantify but is often the largest cost category.
For most mid-market B2B companies, the total annual cost of bad data falls between $2M and $10M when all categories are included.
Strategies That Actually Work
Invest in Prevention Over Correction
Shift your budget from periodic cleanup projects to prevention systems. Required fields, validation rules, standardized picklists, and automated data workflows cost a fraction of what bulk cleanup projects cost and produce better long-term results. This is also why most data enrichment strategies fail — they layer clean data on top of a dirty foundation without addressing root causes.
In HubSpot, build workflows that standardize data at the point of entry: format phone numbers, normalize country names, validate email domains, and flag incomplete records for immediate follow-up. Every record that enters clean is a record you never have to fix.
Establish Data Ownership
Assign clear ownership for data quality to a specific role — a marketing operations manager, a RevOps analyst, or a dedicated data steward. Without ownership, data quality is everyone's problem and nobody's responsibility.
The data owner maintains quality standards, monitors the data health dashboard, runs regular audits, and has the authority to enforce governance policies.
Measure Data Quality Like You Measure Revenue
Build a data quality scorecard and review it with the same frequency and rigor you review revenue metrics. Track completeness (are required fields populated?), accuracy (do field values match reality?), consistency (are the same values recorded the same way?), and timeliness (is the data current?).
When data quality scores decline, investigate and remediate with urgency. Bad data that is caught in a week costs ten times less to fix than bad data that goes undetected for six months.
Tie Data Quality to Business Outcomes
The most effective way to get organizational buy-in for data quality investment is to demonstrate its direct impact on revenue. Run a controlled analysis: compare conversion rates, deal velocity, and forecast accuracy for deals with complete, accurate data against deals with poor data quality. The difference will make the business case for investment self-evident.
The 1-10-100 rule is directionally correct but dramatically understates the true cost. When you account for the trust tax, the compounding effect, the decision cost, and the opportunity cost, bad data is likely the most expensive problem in your organization that nobody is budgeting for. Changing that starts with measuring the true cost and treating data quality as the revenue function it actually is.
For PE firms evaluating acquisition targets, data quality is a measurable proxy for operational discipline. The HubSpot Due Diligence Checklist includes specific data integrity criteria that reveal how seriously a company takes its CRM operations.
Keep Reading
- The Complete HubSpot Guide for PE — Data quality as a value creation lever.
- Hidden Revenue Leak: Poor Sales Data Quality — How bad data manifests in sales operations.
- Data Truth Gap for Marketing Teams — Bad data as root cause of the marketing truth gap.
- Your CRM Is a Mess: 90-Day Cleanup Plan — The action plan to fix it.
How healthy is your portfolio company's CRM? Take the free assessment — 7 minutes, instant results.